Skąd się bierze wszechobecność rozkładu Gaussa? Jednym z powodów jest rozkład dwumianowy. Rozpatrzmy prościutki model. Przyjmijmy, że wzrost dorosłego mężczyzny warunkowany jest czterdziestoma genami w taki sposób, że każdy z nich może zwiększyć wzrost o 2 cm ponad pewne minimum albo nie zwiększyć. Zygota, z której powstaliśmy, wylosowała 40 genów i każdy z nich z prawdopodobieństwem  mógł dodać nam 2 cm wzrostu. Jeśli za minimum fizjologiczne uznamy 140 cm, to możliwy jest każdy wynik z przedziału (140, 220). Oczywiście, nie należy traktować tego przykładu dosłownie. Matematycznie oznaczałoby to 40 niezależnych losowań z prawdopodobieństwem sukcesu
mógł dodać nam 2 cm wzrostu. Jeśli za minimum fizjologiczne uznamy 140 cm, to możliwy jest każdy wynik z przedziału (140, 220). Oczywiście, nie należy traktować tego przykładu dosłownie. Matematycznie oznaczałoby to 40 niezależnych losowań z prawdopodobieństwem sukcesu 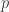 . Rozkład liczby sukcesów wygląda wówczas następująco:
. Rozkład liczby sukcesów wygląda wówczas następująco:
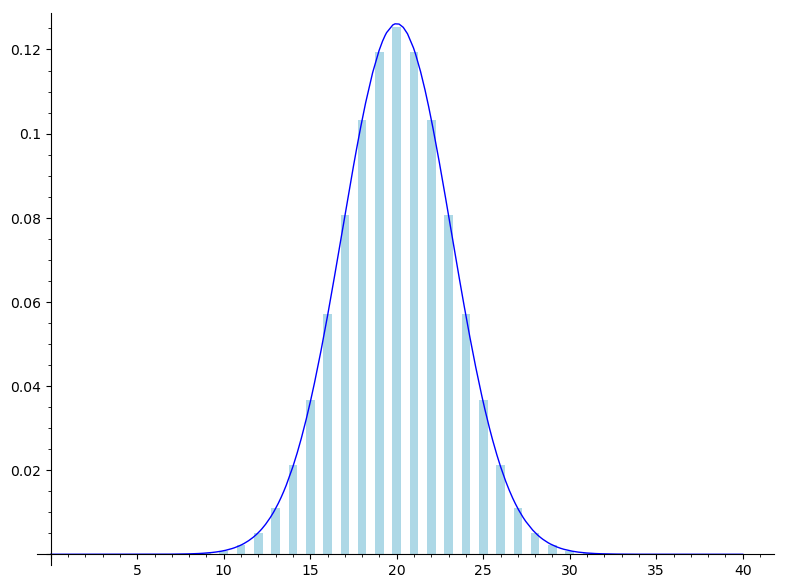
Dyskretny rozkład dwumianowy został tu przedstawiony z przybliżającym go rozkładem Gaussa. Naszym celem będzie zrozumienie, czemu takie przybliżenie działa, gdy mamy do czynienia z dużą liczbą prób.
Zacznijmy od samego rozkładu dwumianowego. Dla dwóch prób sytuacja wygląda tak ( – prawdopodobieństwo sukcesu, 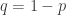 – prawdopodobieństwo porażki):
– prawdopodobieństwo porażki):
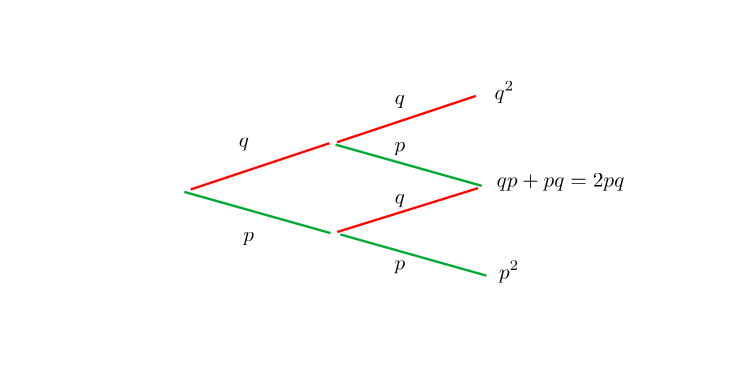
Każda droga z lewa na prawo oznacza konkretny wynik. Wzdłuż drogi prawdopodobieństwa się mnożą, ponieważ są to niezależne próby (definicja zdarzeń niezależnych). Zeru sukcesów odpowiada prawdopodobieństwo  , dwóm sukcesom
, dwóm sukcesom 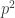 . Jeden sukces możemy osiągnąć na dwa sposoby: sukces-porażka albo porażka-sukces, prawdopodobieństwa należy dodać, jeśli interesuje nas wyłącznie całkowita liczba sukcesów, a nie jej konkretna realizacja. Łatwo zauważyć związek z dwumianem Newtona
. Jeden sukces możemy osiągnąć na dwa sposoby: sukces-porażka albo porażka-sukces, prawdopodobieństwa należy dodać, jeśli interesuje nas wyłącznie całkowita liczba sukcesów, a nie jej konkretna realizacja. Łatwo zauważyć związek z dwumianem Newtona

gdzie mamy n czynników. Każdy wynik to wybór jednego z dwóch składników nawiasu: albo 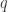 . Mnożymy je kolejno przez siebie, co odpowiada losowaniom, a następnie dodajemy. Oczywiście suma wszystkich prawdopodobieństw równa jest 1. Składniki zawierające
. Mnożymy je kolejno przez siebie, co odpowiada losowaniom, a następnie dodajemy. Oczywiście suma wszystkich prawdopodobieństw równa jest 1. Składniki zawierające 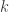 sukcesów mają czynnik
sukcesów mają czynnik  . Wzór Newtona (znany zresztą przed Newtonem) daje nam
. Wzór Newtona (znany zresztą przed Newtonem) daje nam

Prawdopodobieństwo sukcesów jest równe

Jest to nasz punkt wyjścia. Przy dużych wartościach  obliczanie symboli Newtona było w XVIII wieku trudne, ponieważ występują tam silnie dużych liczb. Zwłaszcza w rejonie środka rozkładu obliczenia takie były kłopotliwe, ponieważ zostaje wiele czynników, które się nie skracają. Abraham de Moivre, francuski protestant zmuszony do emigracji z ojczyzny z przyczyn religijnych, spędził życie w Londynie, ucząc matematyki. Podobno jeździł po Londynie od ucznia do ucznia z kolejnymi kartkami wyrwanymi z Matematycznych zasad Newtona i w wolnym czasie zgłębiał treść tej masywnej księgi. De Moivre podał sposób przybliżania
obliczanie symboli Newtona było w XVIII wieku trudne, ponieważ występują tam silnie dużych liczb. Zwłaszcza w rejonie środka rozkładu obliczenia takie były kłopotliwe, ponieważ zostaje wiele czynników, które się nie skracają. Abraham de Moivre, francuski protestant zmuszony do emigracji z ojczyzny z przyczyn religijnych, spędził życie w Londynie, ucząc matematyki. Podobno jeździł po Londynie od ucznia do ucznia z kolejnymi kartkami wyrwanymi z Matematycznych zasad Newtona i w wolnym czasie zgłębiał treść tej masywnej księgi. De Moivre podał sposób przybliżania  oraz wartości silni – to drugie przybliżenie nazywamy dziś wzorem Stirlinga od nazwiska drugiego matematyka, który w tym czasie zajmował się tym zagadnieniem.
oraz wartości silni – to drugie przybliżenie nazywamy dziś wzorem Stirlinga od nazwiska drugiego matematyka, który w tym czasie zajmował się tym zagadnieniem.
Zaczniemy od . Jeśli spojrzeć na histogram z obrazka rzuca się w oczy ogromna dysproporcja miedzy prawdopodobieństwami różnych wyników. Dlatego będziemy szukać przybliżenia nie dla , lecz dla 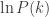 .
.
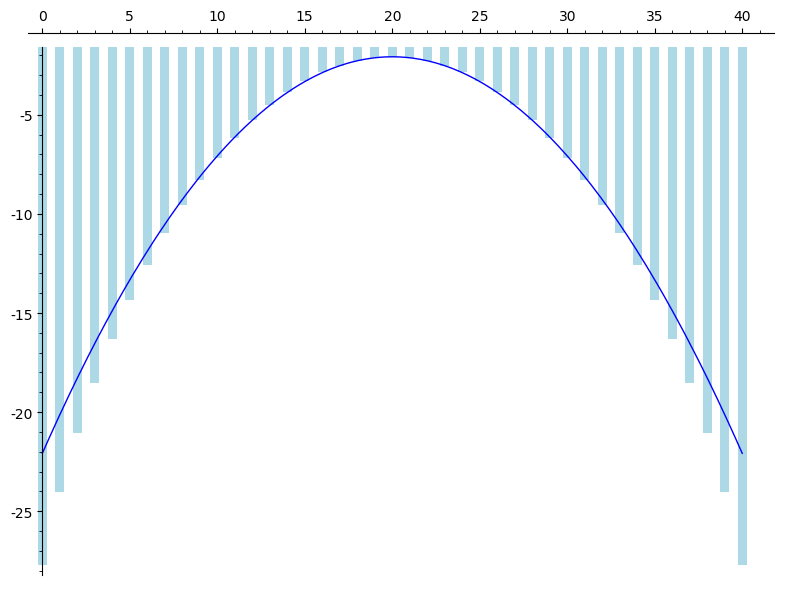
Wykres przedstawia histogram , a także przybliżającą go parabolę. Każdą przyzwoitą funkcję możemy przybliżyć rozwinięciem Taylora:
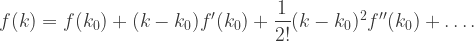
W maksimum znika pierwsza pochodna, mamy więc

Naszą funkcją jest
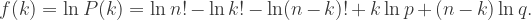
Potrzebujemy pochodnej z silni dla dużych wartości oraz 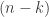 . Pochodna to przyrost funkcji odpowiadający jednostkowemu przyrostowi argumentu. Ponieważ
. Pochodna to przyrost funkcji odpowiadający jednostkowemu przyrostowi argumentu. Ponieważ

powinna ona być równa
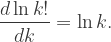
Poniżej uzasadnimy to precyzyjnie, choć ostatni wzór powinien być zrozumiały intuicyjnie: nachylenie funkcji logarytmicznej stopniowo maleje, więc sumę można coraz lepiej przybliżać za pomocą pola pod krzywą.

Odpowiada to przybliżeniu

Warunek na maksimum funkcji przybiera postać

Druga pochodna równa jest

Ostatnia równość daje wartość pochodnej w punkcie 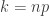 . Nasze przybliżenie przybiera więc postać
. Nasze przybliżenie przybiera więc postać

Jest to rozkład Gaussa o wartości średniej 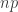 oraz szerokości (odchyleniu standardowym)
oraz szerokości (odchyleniu standardowym)  . Wartość
. Wartość  można wyznaczyć z warunku normalizacji: pole pod naszą krzywą powinno być równe 1. Można ściśle pokazać, że przy dużych wartościach wyrazy wyższych rzędów są do pominięcia przy obliczaniu prawdopodobieństw: różnice między parabolą a histogramem na wykresie dotyczą sytuacji, gdy prawdopodobieństwa są bardzo małe.
można wyznaczyć z warunku normalizacji: pole pod naszą krzywą powinno być równe 1. Można ściśle pokazać, że przy dużych wartościach wyrazy wyższych rzędów są do pominięcia przy obliczaniu prawdopodobieństw: różnice między parabolą a histogramem na wykresie dotyczą sytuacji, gdy prawdopodobieństwa są bardzo małe.
Przyjrzymy się teraz bliżej obliczaniu silni z dużych liczb. Zacznijmy od następującej funkcji zdefiniowanej jako całka:
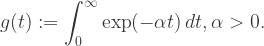
Różniczkując ją kolejno n razy po 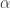 i kładąc na koniec
i kładąc na koniec  , otrzymamy
, otrzymamy
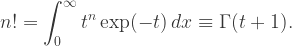
Otrzymaliśmy funkcję gamma Eulera, która jest uogólnieniem silni, ponieważ zdefiniowana jest nie tylko dla wartości całkowitych , lecz może być uogólniona na płaszczyznę zespoloną i określona wszędzie oprócz argumentów całkowitych ujemnych. Nam wystarczą tutaj wartości rzeczywiste dodatnie, szukamy przybliżenia dla dużych . Zapiszmy funkcję podcałkową w postaci wykładniczej i zastosujmy rozwinięcie Taylora wokół maksimum, dokładnie tak jak powyżej dla funkcji :

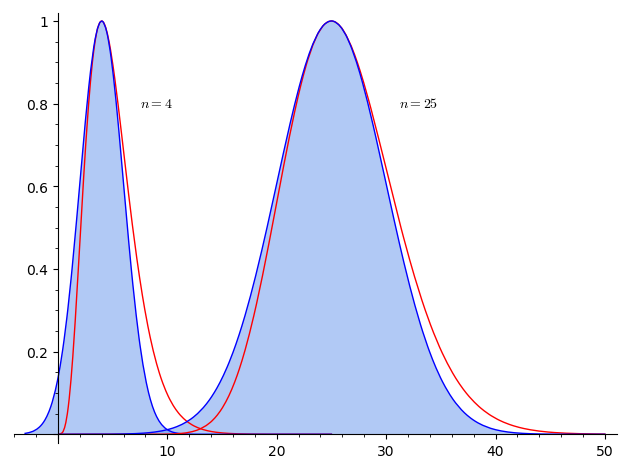
Wykres przedstawia przybliżenie gaussowskie oraz (na czerwono) wartości funkcji po wyłączeniu czynnika 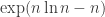 . W przybliżeniu gaussowskim możemy rozszerzyć dolną granicę całkowania do
. W przybliżeniu gaussowskim możemy rozszerzyć dolną granicę całkowania do  , co nawet zmniejsza błąd przy niedużych wartościach , a niczego nie psuje przy dużych wartościach . Jeśli przeskalujemy funkcję gaussowską tak, aby miała jednostkową szerokość, porównanie wypadnie jeszcze lepiej.
, co nawet zmniejsza błąd przy niedużych wartościach , a niczego nie psuje przy dużych wartościach . Jeśli przeskalujemy funkcję gaussowską tak, aby miała jednostkową szerokość, porównanie wypadnie jeszcze lepiej.

Widzimy więc, że można ostatnią całkę wziąć po całej prostej. Jej wartość jest równa  . Otrzymujemy wzór Stirlinga:
. Otrzymujemy wzór Stirlinga:

Zaznaczyliśmy też wielkość następnego wyrazu w szeregu malejących potęg . W wielu zastosowaniach można pominąć zupełnie całkę gaussowską i wnoszony przez nią wyraz . Jak się trochę popracuje nad dalszymi wyrazami rozwinięcia Taylora, można otrzymać i tę poprawkę  .
.
Pierre Simon Laplace rozwinął techniki szacowania wartości asymptotycznych całek. Jego wyprowadzenie wzoru Stirlinga było elegantsze, lecz rachunkowo trudniejsze (wymagało odwrócenia rozwinięcia w szereg). Laplace wykazał także, iż sumy zmiennych losowych zachowują się jak zmienne gaussowskie także w ogólniejszych sytuacjach niż ta przez nas rozpatrywana. Innymi słowy pierwszy zauważył, że zachodzi tzw. centralne twierdzenie graniczne. Ścisły dowód pojawił się znacznie później.

